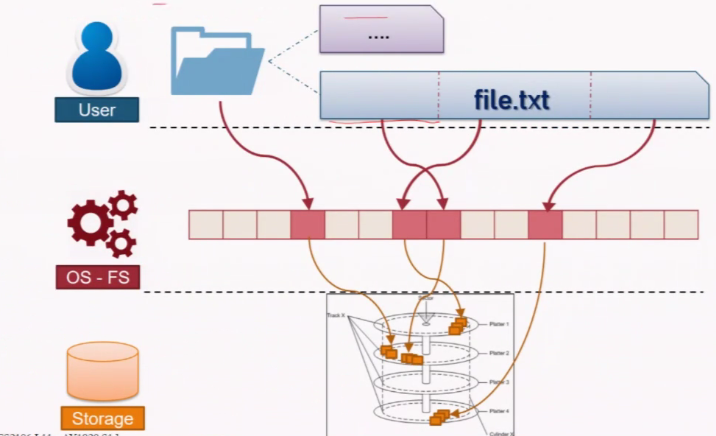
- File systems are stored on storage media
- Concentrate on hard disk
Layout
-
General Disk Structure
- 1-D array of logical block
- Logical block : Smallest accessible unit (512 bytes to 4KB)
- Logical block is mapped into disk sector
- Layout of disk sector is hardware dependent
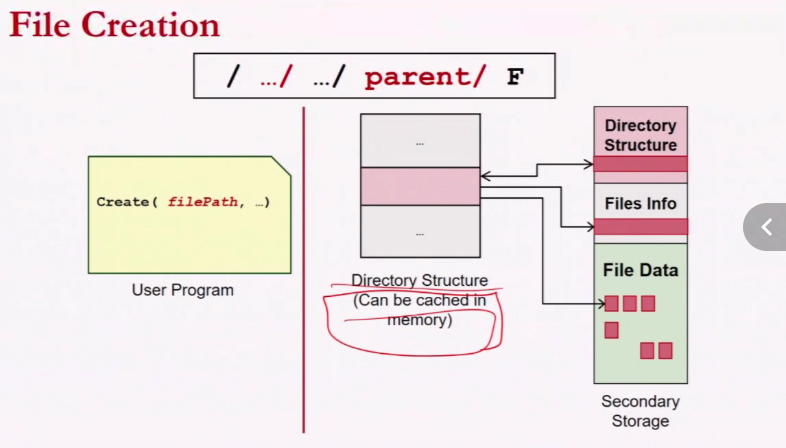
Disk Oraganisation
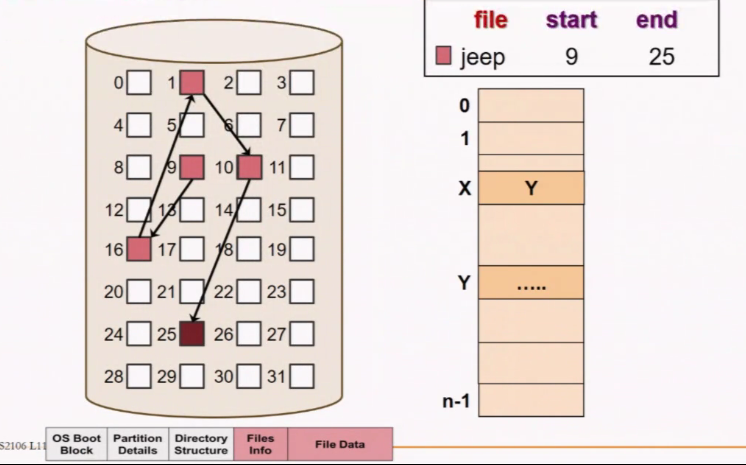
There is an array of logical block which is divided into partition. Each partition has a MBR (Master Boot Recognisation)
MBR contains:
- Partion table
- Simple boot code
Partion contains:
- OS Boot block: Every partiton can have a different file system
- Partition details: Tells whats the free space/how many blocks in total/what type of file system
- Directory structure: How exactly the infomation is stored for a particular file type
- File Info: What block each file is using/name/permission
- File Data
note that the infomation can be mixed together
Implemntation details
A logical view of a file is a collection of logical blocks.
When the file size is not a multiple of logical blocks, the last block might have internal fragmentation
What ever we have at the last block is a wasted space that cannot be use. (Due to the overhead)
A good file implementation must:
- Keep track of logical blocks
- Allow efficient access
- Disk space is utilized effectively (Little overhead)
File infomation
Contiguous Block Allocation
Allocation must be contiguous. It will be very easy to access (Just by going to the offset)
Just give consequtive blocks.
Infomation to store:
- Start: Where is the starting point?
- Length: How long is the data?
What is the maximum file size for file “tr” in the current slide Answer: 5, because its the number of space free behind it
We can see that the file size is fixed when allocated.
Pros:
- Manage easy
- Access Easy
- Easy traverse
Cons:
- Fixed size (Cannot grow much) specified in advance
- Might have issues due to external fragmentation
Linked List Allocation
Infomation:
- Start
- End (For appending)
- Use a pointer
Pros:
- Can grow
Cons:
- Traversal problem (slow)
- Overhead (Pointer)
- If one block is corrupted, the rest is lost
File block Allocation: Linked List v2.0
- Having a link list as a seperate structure
- Known as FAT (File allocation table)
- Block pointers is stored in a single table
- The last file is signified by the -1
Pros:
- Can be kept in memory (Finding the next block is faster)
- Simple and efficient
- Light weight
the array like structure is stored in memory thus we do not need to keep accessing the disk
Cons:
- If each entry is 4 bytes, we will have 3GB needed for the fat table
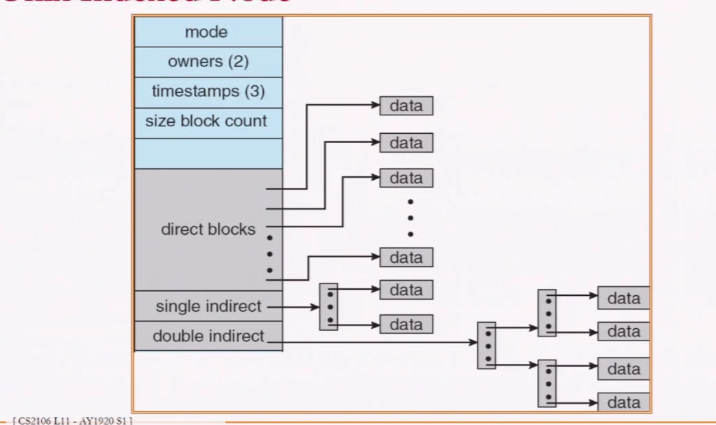
Index Allocation
- Have an block called index block which show where the infomation is stored
- Use of index table
- IndexBlock[N] == Nth block address
Pros:
- Less memory overhead
- Fast direct access
Cons:
- Limited Maximum file size
- Max no. of blocks == no. of index block entries
- Index block overhead
Other schemes:
- Multilevel index: Similiar to multi-level paging
One disadvantage is that we need n number of access if there are N levels
- Linked scheme
- Combined scheme: Combination of direct index and multilevel
Free Space management
- Know which disk block is free
Allocate:
- Remove free disk block from free space list
- Needed when file is created or enlarged (appended)
Free:
- Add free disk block to free space list
- Needed when file is deleted or truncated
BitMap
-
Each diskblock is represented by 1 bit
0 - occupied 1 - free
Pros:
- Good set of manupilition
Cons:
- Keep in memory
Linked list
- Use a link list of disk blocks
- Each disk blocks contains:
- A number of free disk blocks number
- Pointer to the next free
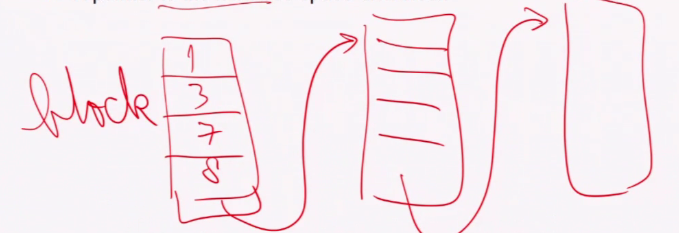
Pros:
- Easy to locate free block
- Only first pointer needed in memory
- Other blocks can be cache for efficiency
Cons:
- High overhead
Directory Structure
- How we store the directory structure
Directory is part of the file system but it is not only one part that stores purely directory This help us to tell us how the files are stored
- Keep track of files in directory
- Map the file name to the file infomation
Remember:
- Open file before using
- Locate the file infomation using the pathname + filename
Figure out the root and the structure
/dir2/dir3/data.text - this is a full path name
Subdirectory is usually stored at a file entry with special type in a directory
Subdirectory will have a special bit in its meta data
Linear List
- Directory consist of a list
- File name
- Pointer to file infomation
- File infomation
- Possible other meta data
We can use an hashtable to improve the linear search [O1]
HashTable
- Each directory contains a Hashtable of size N
- To locate file by name, file name is hashed into index K from 0 to N-1
- HashTable[k] is inspected to match file name
In general, we will try to improve the search
Pros:
- Fast look up
Cons:
- Limited size (some)
- Collision
File infomation
- Do we want to store the meta data in the directory or have it seperate outside the file
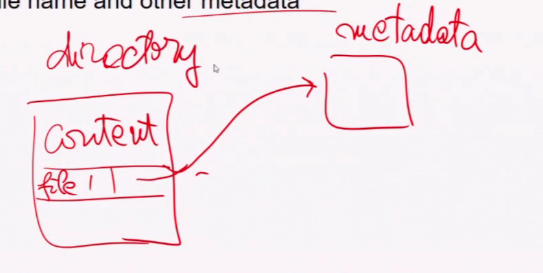
- Store Everything in directory entry
- Store only file name and points to some data structure for other info
File System in Action
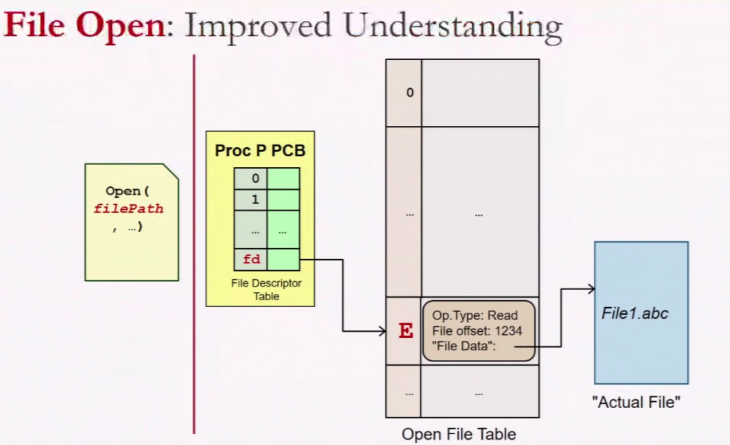
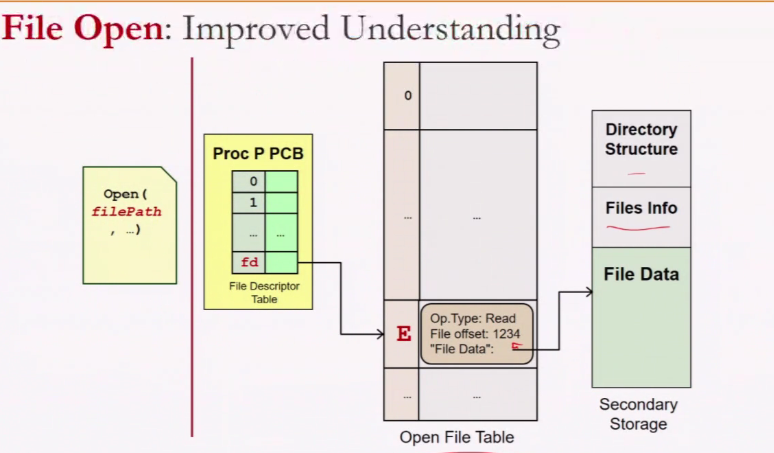
If the file is already open already, it does not matter, we just get a new entry in the file table (However, there are file systems where only one process can open)
How can we use the same entry in the open file table within the same process
- Dup
- fork
How will the OS know that you have 2 fd pointing?
There is a reference count in the file table. If one process closes the fd and another uses, the reference count decreases only and it continue to exist
How will file know that you have the file link in multiple directory
Reference count that say how many process have access to this. Reference count is in the file info meta data
- File table: Dynamic
- Secondary storage: Static
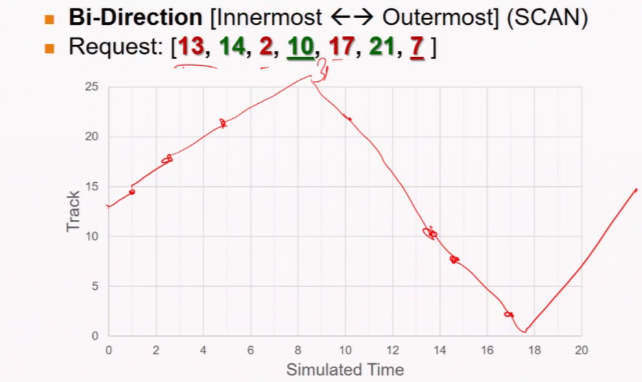
Disk I/O Scheduling
- Magnetic disk
The problem:
- Waiting time
- Seeking time
- Balance
We must have responsiveness
Algorithms
- FCFS
- SSF (Shortest seek first): Base on the position of the head
- Scan
- Deadline
- Sorted
- FIFO (R/W)
- noop: No sorting
- cfq (Completely fair queueing)
Base on time slice or per process sorted queues
- bfq (Budget fair queueing) (Multiqueue) Based on number of sectors requested
Scan: Disk head movement
Read blocks on the way base on the direction