Motiavation
Assumptions:
- The physical memory is large enoguh to contain one or more process with complete memory space
Logical proccess » physical
Basic Idea
Secondary storage capacity » Physical
- Split the logical address into smaller chunks
- Some chunks reside in physical
- Others are store in secondary
- This is like an extension of the paging scheme
Extended page scheme
- Use page table: Virtual -> physical
New Addition:
-
Two page types
- Memory resident (Pages in physical memory)
- Non memory resident (Pages in secondary storage)
- Use a (Is memory resident?) bit in page table entry
We need to keep an extra bit to keep track of what the file can do
- CPU can only access memory resident pages
Page - fault: When CPU tries to access non memory resident page
Accessing Page X: General Steps
- Check page table
- Page x is a memory resident
-> Yes: Access physical
-> No : Continue
- Page fault
- Locate page in sec storage
- Load page
- Update page table
- Reexecute the same instruction and go step 1
** In an multi-threaded system with many cores, when there is a trap to the OS, can some other thread run at the time. **
The OS is not activitely fetching and running, there is a special piece of hardware call DMA controller which is programmed to bring certain memory without troubling the cpu, it will notify the CPU after it happens thus other process can continue to run even thou it is fetching memory. The process is not going to be involve any of the cpu cores.
The secondary storage access is very slow.
** If any 10 percent of pages are in main mem, what fraction of memory access will end up causing page fault **
If memory access result in page fault == Thrashing
Locality Principals
- Most of the time are spent on a small part of code
- In a time period, access are made to relatively small part of data
** Temporal ** Memory address which are use are likely to be use again
- Loaded to physical as it is likely to be access again
Spatial
Memory addresses close to a use address is likely to be used
- Page contains contiguous location that is likely to access in near future
Page Fault
We can indicate which frame is needed from the secondary storage.
-
CPU request pages from MMU whcih contains the TLB and the logic to translate virtual to physical
-
MMU check if the page is in TLB, if its not it will fetch the page and replace it in its page table.
-
RAM is the physical memory
-
Disk is in the secondary storage
The page table is stored in the part of the phyiscal memory where it is dedicated to the OS
We can have multiple parallel access and translation. The OS is responsible for flushing the TLB when there is a context switch.
Summary
- Complete seperate logical memory address from physical memory
- Amount of physical memory no longer restrict the size of logical memory address
- More efficient use of phyical memory
- Page currently not needed can be on secondary storage
- Allow more processes to reside in memory
- Improve CPU utilization as more process are able to run
The bottle neck could be memory as one process can use up all the memory, with virtual memory we can improve this and have more process running.
If a thread experience a page fault does that means that all the other threads from the same process are block?
No
What if we switch to another thread and it generates the same request that loads the same address
Trap to memory and OS will figure out that it does not need to do 2 request. They will sleep for all process that are waiting for that IO and there is an interrupt to wake up all waiting process once it is loaded.
Common application of Virtual Memory
Demand Paging
The process is starting with all the pages in the secondary storage. When accessing it, will generate a page fault. Only when we need it, then we will bring the page into the physical memory.
Allows process to run unlimited virtual space on a machine with limited physical
There are alot of synchronisation involves when it comes to accessing memory and there are many codes in the linux kernel that ensure that the entire system is properly synchronised in OS level. OS cannot access a page that is being used, only when the page is flush from a buffer then it can be access again. The buffer is called a victim cache.
Which system designg principals demand paging follow
Laziness, this is very commonly use together with speculation in OS. This is only because we have not enough resources. e.g Copy on write
- Huge page table with large logical memory space
- Page table structures
- Limited number of resident memory space
- Page replacement algo
- Limited physical memory frames
- Frame allocation policies
Aspects of virtual memory
Page Table Structure
Page table infomation is kept with the process infomation and takes up physical memory space
If we have 2^p pages in logical memory space
- P bits to specify one unique page
- 2^p page table entries (PTE) with:
- Physical frame number + additional infomation bits
2 Level paging
- Have a number of page tables that response to differenrt regions of the physical memory
- Reduce size of page tables
- Useful page must remain the space
- Reduce useless page
Split the virtual address into:
- Base address
- Kept in register
- Use it to index the first structure
- Pointer to page table
- Use to get the page frame number
- Index based on the base address
- Use the offset to get physical address
there is no external frag and internal is inherited from pages
Cons:
- Need for 3 memory accesses
- Page director
- Page table
- Physical
The tree will grow and we have to traverse the tree until we find the page table. However, our TLB can bypass this. The one that is important is that the process must have a valid pointer.
MMU caches are a complement to TLB which cache some part of the directory
Pros:
- Less size used (from MB -> KB)
Each page must be fit exactly correct, an invalid entry means that the entire subtree does not exist
We keep the infomation of how to translate from virtual to physical in the TLB
Inverted Page Table
Given that we have a giant virtual address space compared to the physical. What if we have a structure that can tell us who occupies which virtual address givene the physical address and has a lesser overhead
- Page table is a per process infomation
- For every frame, remember who has access.
** Why do we need a process ID**
We can have multiple process residing in the same page frame, this means they are sharing the same memory. We use the PID as an index in the inverted page table. We can use hash table to convert the physical address and guess from the inverted page table.
- Verify the PID
- Verify the Page
Are there any checks on the integrity of the page table?
The cache structure will have a valid bit that checks if the page entry is relevant or not.
More
-
How to structure the page table for efficientcy -> Page table structures
- Each proccess has limited number of resident memory pages
-
Page replacement algo
- Limited physical memory frames -> frame allocation policies
Page Replacement Algorithms
No free physical memory frame during a page fault:
- need to evict (free) a memory page
Things to consider:
- Is the page clean or dirty
Clean = not modified -> no need write back
Dirty = Modified -> need to write back
- Is the page shared?
A shared page is not a good candidate to replace A shared page also means that it is in multiple tables
Modeling memory references
- In actual memory references:
Logical address = page number + offset
The algo usually do not care about the offset
- Only page number is important to page replacement algo
The page fault includes a) access/latency to storage (Disk) [Dominant] b) ALG c) Contention in OS

However, our assumption that the latency might be the bottleneck might be wrong. Sometimes it can be the contention in the OS
Optimum Page Replacement (OPT)
- Beladys algorithms
Assumes that we know the future, replace the page that will not be used again for the longest period of time.
-> Guarentees the minimum number of page faults
But we do not know the future
Still useful
- As a base comparison for other algorithms
- THe closer to OPT == better algo
- Assumes we know the order of references
- WE also know the next time it is needed
- We will track the number of page faults
Basis:
- Everytime we load a frame, we will check if we have space and need it the next time in the future.
- If we do not need, we can take a note.
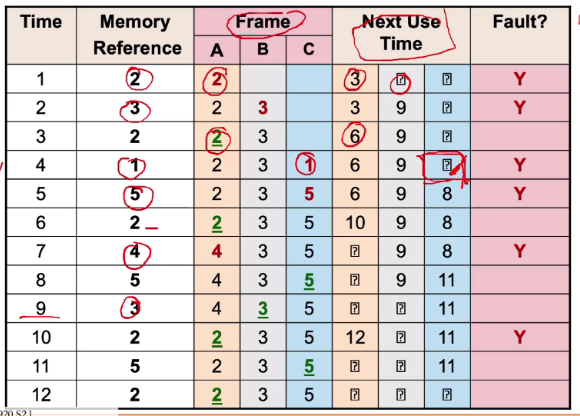
FIFO
Memory are evicted based on their loading time -> Evict the oldest memory page
Implementation:
- Maintain a queue of page
- Remove the first page if replacement is eneded
- Update the queue during a page fault
This is simple as it does not need a hardware support. It also require simple OS structure.
- Track the loading time
- We need keep a time stamp for every page
- Maintain a queue
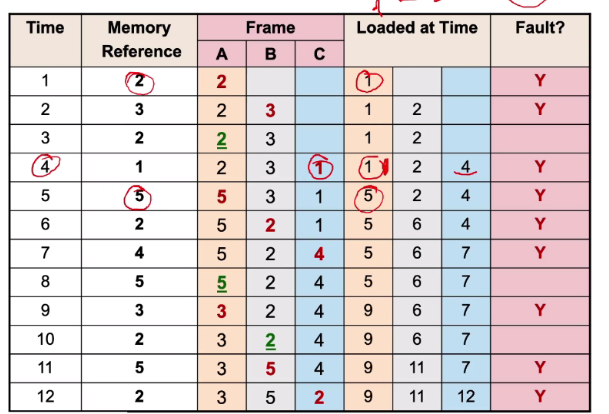
- We replace page 2 with page 5 since page 2 was first in the queue
Problems:
- Increased of memory capacity should means that fewer page fault. But FIFO doesnt work for this case
e.g 1 2 3 4 1 2 5 1 2 3 4 5 use 3,4 frames
- 3 frames -> 9 faults and 3 hits
- 4 frames -> There is more faults compared to 3 frames
This opposes the idea from Belady’s algo
Reason:
- FIFO does not explout temporal locality
Does not prioritise pages that has been recently accessess. Pages are chosen base on the order that they arrive
LRU
Makes use of temporal locality
- Replace the page that has not been use in a longest time
Accesses in the future are going to be the same as the access in the past. Have not use for sometime -> most likely will not be used again
- Does not suffer from belady anomaly
Problems:
- Hard to implement
- Requires timer to keep track of last access time
- Need to look at every page’s time stamp
- Need substantial hardware support
We can use an approximate version rather than looking through every single page. We just ensure that the page we are evicting is not recently accessed
- Do not track time loading of page
- Track the latest access time
- Update the last use each time it is used again
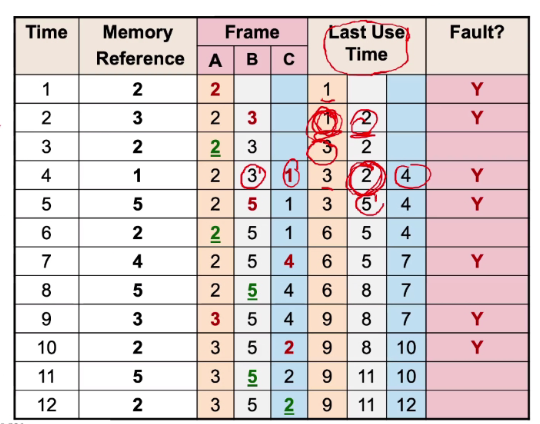
We need space for page 5, since page 3 is the last recently used, we replace page 3 with 5
Implementation
- Keep a counter
Increment each time when access memory. Remember the counter in some structure.
- Requires some hardware support to update
- Need to search the entire list of candidates
- We might cause a counter overflow
- Use a stack
Maintain a stack of page numbers. The top is the most recently access and the last one was the least recently access. Each time there is a page fault, we will look at the bottom of the stack and we will know which is the one to replace.
- Need to reshuffle the stack each time we access
- Impractical
- Hard to implement for page
Second-Chance page replacement (clock)
Modified version of FIFO, gives a second chance to pages that are accessed.
Keeping track of the PTE using a reference bit
1 = accessed 0 = not accessed
It is set by the hardware to 1 each time the page is accessed
- Look at the oldest page
- If bit is 0, replace it
- If it is 0, page is given a second chance
- Reference bit will be set to 0
- Move on to the next page
- Continue step 1 with the next page in the FIFO
If all pages has bit ==1, it degenerates into a FIFO algo
It is not a widely used algo now
- We do not keep the exact time stamps
Frame Allocation
There are N physical memory frames
There are M processs competing for frames.
What is the best way to distribute frames?
- Equal
N/m frames
- Proportional
SizeP = size of process p, sizeTotal = total size of all processes
Each proccess get sizep/sizetotal* N frames
Frame allocation and page replacement
Local replacement: Victim page are selected among pages of the proccess that cause page fault
Pros:
- Performance is stable
- Does not interfere with other process
Cons:
- if frames not enough, hinder the process progress
Global replacement: Proccess P can take a frame from proccess Q
Pros:
- Allow self-adjustment
Cons:
- Does not gurantees performance isolation
- Frames allocated to a proccess can be different from run to run
Frame allocation and thrashing
If the number of page fault is more than page hits, this is thrashing
- Heavy I/o to bring non resident pages into RAM
-
Thus we can limit the number of processes to sustain the system
- Hard to find the right number of frames:
Global:
- Thrashing steals page
- Cause other process to trhash (cascading thrashing)
Local:
- Thrashing is limited to one proccess
- Single proccess can hog I/O and
-
The set of pages referenced by a process is relatively constant in a period of time -> Known as working set
-
Set of pages can change -> Different programs phases required different data
Working set model
- Trying to capture what the process needs
- Well defined number of pages
- Most of the replacement algo will result in low page fault
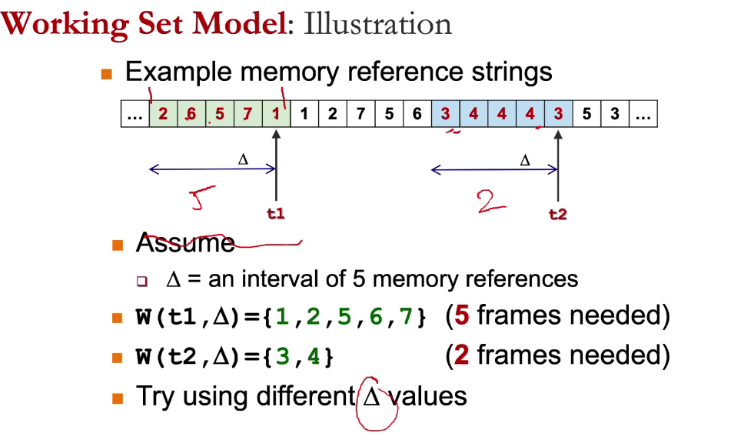
Defines a working set window v
- W(t,v) = active pages in interval at time t
-
Allocate enough frames in pages in W(t,v) to reduce possibility of page fault
- Each new phase swap will show an increase in page fault
- After a new phase switch, there will be a stable region where to working set is the same for a long time
Choosing v:
- Too small: May miss pages in current
- Too big: May contains pages from different working set
It is hard to find which v that will work for everybody