CS2106: Lecture 2 - Process Abstraction
Recap:
Efficient Hardware Utilization
- OS should provide efficient use of hardware resource
- Allow multiple program to share the hardware
- OS provide abstraction to encapsulate the execution of a program
C sample Program and Assembly Code
int i = 0
Assume the address of i is at 4096 lw $1, 4096 #loads the value at 4096 addi $1, $0, 0 # store $1 = 0 sw $1 , 4096 # i =0
i = i +20
lw $2, 4096 #store i in $2 addi $3, $2, 20 #add $3 = $2 +20 sw $3, 4096 #i = i +20
Program execution(Memory)
There is a component in the memory that contains the text for instruction. Under the text memory is the data memory for global variables. The lifetime of these variables is the same as the life time of the function. The compiler has access to these memory.
e.g int j; The compiler is going to put this data into the BSS (Segment), it allocates a space in the data memory for this variable. The system auto sets it to 0.
Computer Organisation
The computer contains 2 main pieces, the memory and processor. The processor is on the CPU chip. Because the memory is so slow, we have two cache components that are very fast. They are data cache and instrcution cache. The process fetches instruction by instruction and decodes them, it also fetches any data from memory if needed and decode it. Register is also use so that there is no need to keep going to caches to get the data.
Memory:
-
Storage for instruction and data
-
Manage by OS
Cache:
-
Fast
-
Hardware managed
-
Duplicate memory for fast access
-
Usually split into instruction and data cache
Fetch unit:
- Load instruction to memory
- Location indicated by a special register (PC)
Functional Units:
- Carry out instruction execution
- Dedicated to different instruction type
The protocol is to fetch the instruction, read the operands if its needed. Some instruction does not need operands, ie jump
When a program is under execution, there are more information:
- Memory context: text and data
- Hardware context: General purpose register, program counter (PC) Memory/storage hierarchy
- Size increases > Speed decreases > Cost per bit decreases
Register: Access directly by instruction
Cache: Not visible to software
Main memory: Access through load store instructions
Process Abstraction
Information describe an executing program
A process/task/job is a dynamic abstraction for executing program. The information required for running program contains:
- memory
- Hardware
- OS Whatever the OS needs to keep track of the process
Function Calls
How to allocate memory space for function declared variables?
Control flow
-
Recursive call?
-
Calling functions? Where to store the memory and the stack?
Issues
-
Jump from function body
-
Need resume when function call is done
-
Store PC of the caller
Data storage Issues
- Need to pass parameters to the functions
- Need to capture the return result
- May have local variables declaration
Where are we gonna store all these?
Stack Memory
The stack is a memory region to store information function invocation
- LIFO structure
The data is temporary.. once it gets push out of the stack, its out.
Stack frame
The data that is stored onto the stack memory. It belongs to one particular function.
Stack frame contains:
- Return address of caller
- Arguments (Para) for fn
- Storage for local variables
Stack Pointer
A pointer that points to the top of the stack region. Most CPU has a specialised register for this purpose. The stack frame is added on top when a function is invoked. Stack can grow towards higher or lower addresses
- platform dependent.
Setup stack frame
- Called function call convention
- Main diff:
Prepare to make function call
Caller: Pass para with register and /or stack
Caller: Save PC on stack
Transfer control from caller to callee
Callee: Save the old stack pointer (SP)
Callee: Allocate space for local variable of callee on stack
Callee: Adjust SP to point to new stack top
Who does the setup? => The compiler
On returning from function call:
Callee: Place return result on stack
Callee: Restore saved stack pointer
Transfer Control back to caller using saved PC
Caller: Utilize return result
Caller: Continues execution in caller
Just decrement the stack pointer.
Frame pointer
- To facilitate the access of various stack frame items
- Frame pointers points to a fixed location in a stack frame
It is to access something that is in the middle of the stack. At some point, we will remember the value of the stack pointer and the frame pointer so we can remember values of other variables via referencing. The stack is part of the memory!!! The usage of these is platform dependent
When do we use the stack or frame pointer?
Frame pointer points to the bottom half of the stack frame. FP does not move
Stack pointer points to the top of the stack frame. SP moves.
Stack Pointer:
- When more values are added/popped
- Referencing values at the top of the stack
- Changing values on the top of the stack
- Returning the FP back to the original position
- Setting the FP to the middle of the stack
Frame Pointer:
- Accessing values from the middle of the stack
- Accessing parameters
- Can be use to store
FP and SP can be use interchangably providing considering the limitation that is given for each of the pointers:
- Pointers must be pointing to somewhere on the stack frame
- The values are closer to that pointer
- FP is fixed, SP can move upwards
Saved Registers
The number of GPR on most processor are limited. When GPR are exhausted:
- Memory temporary hold value
- GPR value can be restored afterwards
- GPR can then be reused for other purpose This is register spilling
Dynamically Allocated Memory
Because the stack memory is only temporary, DAM is used to allocate a memory to be more permanent. DAM allow the memory to leave only when it wants.
e.g malloc() function call in C new keyword in c++ and java
The DAM is stored in a heap memory region. Usually the heap will grow in the other direction towards the stack. Unlike stack, it can be fragmented.
Memory context: Text, data, stack and heap
Hardware context: GPR, PC, Stack pointer, Stack frame pointer It needs to be protected (status), if any interruption, there will need to save
Operating system:
Managing
- Harder due to variable size
- Allocation and deallocation timing is unknown
Extras: 1) Why does the compiler knows the address if a global variable? The compiler only know the size of the program and the size of the variables.
Having two pointers, we can find the address using the relative position of two pointers. They do not need to know the exact address. There are many ways on finding the address. Different compilers will come out with different address -> Under memory management.
2) Why not use data structures like heap to replace stack?
There is another similar heap used to manage but no it does not allow for fragmentation.
IPC and Synchronization
PI (Process identification) is use to distinguished process from each other and is often used even till the hardware level. It is a software concept but is communicate till hardware.
Process:
Memory: Text, data, stack and heap Hardware: GPR, PC, stack pointer, stack frame pointer OS: PID, Process state
Design decision:
- Reuse PID? => yes (Can we run out of ID?)
- Are there reserved PID => yes
- Does it limit the max no. of processes => 2^64 (There is alot)
Process state
- A process can be running or not running (running another process)
- A process can be ready to run but not executing
- State keep track on the status (indication of execution)
The process of switching from one process to executing is called context switch. We are switching the context and by that we are switching everything, the memory.. hardware etc..
*Lets say we have process p1 running and p2 is ready. Some point in time, p1 may volunteer to relinquish the CPU. That is a system pause (eg.). Every process is selfish and want to finish. One reason that p1 want to stop is because it wants to wait for data or p2 interrupt.
When interrupt, the process scheduler is invoked.
(Preemption)
P1’s context is saved and stored somewhere before p2 is runned.
Context switch involves saving everything is relevant into some data structure and loading the next process's screenshot.
Generic 5 state process model
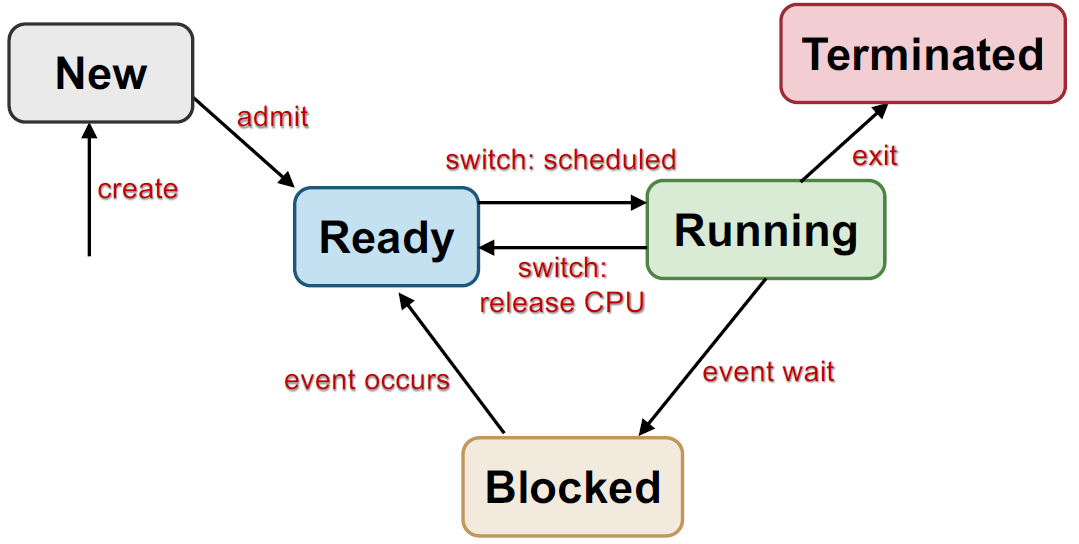
This is a textbook model but is not generally used.
New
- New process created
- Might be initializing
Ready
- waiting to run
Running
Process being executed on CPU by scheduler *Scheduler decides on which component is run. How many process is running is defined by CPU component.
Running -> Ready Can be voluntarily or involuntarily.
Blocked
Process waiting for event (Sleeping) Cannot execute until event is available We CANNOT go from blocked state to running, we need to go ready. The process will wait to be picked up by the scheduler.
Maybe we are waiting for some input or data (ie user io), the process will not occupy the CPU while it is blocked and let other process to continue.
Terminated
Can be terminated at any point, gracefully or forcefully. May require OS cleanup
State transition (5 stage model)
Create (nil-> new)
- New process is created
Admit(New-> ready)
- Process is ready to scheduled for running
Switch(ready-> running)
- Process selected to run
Switch(Running-> ready)
- Process gives up CPU voluntarily or preempted by scheduler
Event wait(Running->blocked)
- Process request event/resources/service that is not available in progress i.e.. syscall, waiting for IO
Event Occurs(Blocked->ready)
- Event occurs, process can continue
Given n process, with one cpu, less than one or equal process can be in running states, one transition at a time With m cpu, less or equal to one process in running state and possibly parallel transition
Transitioning in their own time.
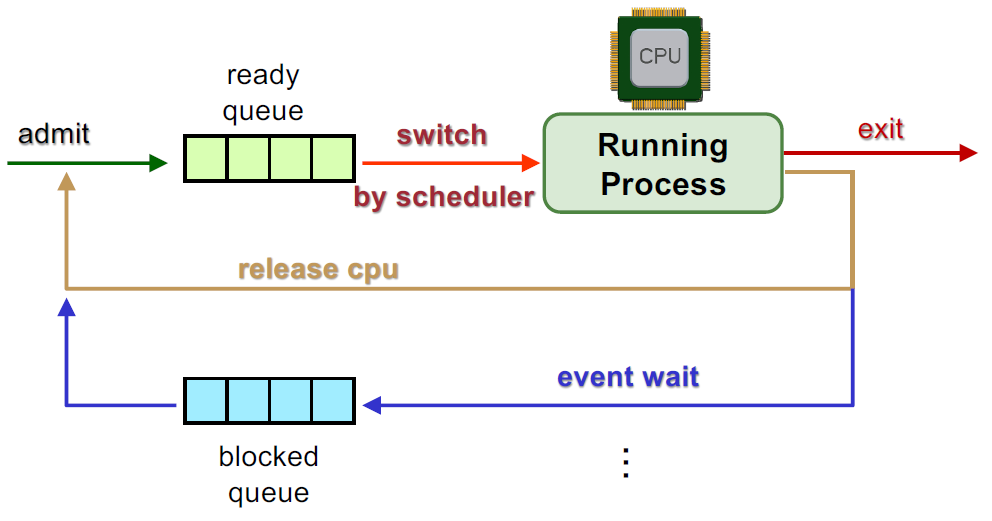
Queuing theory
Represent the process when it is admitted, goes into the queue. When process released the CPU, it can either go into block, return to queue or terminate. The block itself is a queue.
Process table and Process control block
PCB is used for storing the context of the process. (or PTE) The kernel maintains PCB of all processes.
Issues: Scalability - How many concurrent process can we have? Efficiency - Minimum space wastage
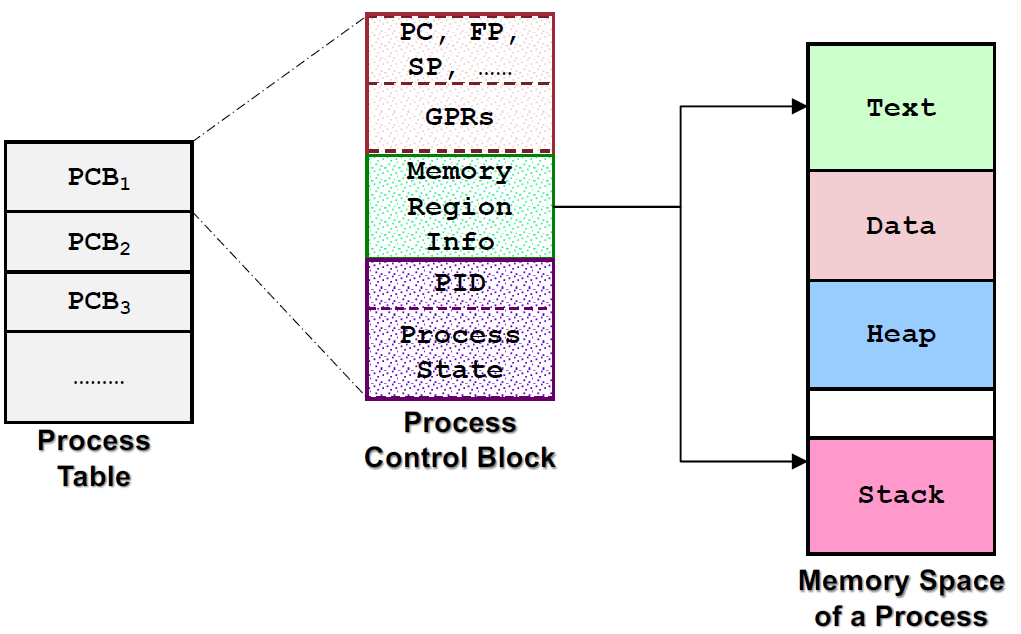
The process block have
- GPR
- Memory Info
- PID
- Process state
This include memory mappings on where the memory space of the processes are. They are often linked in with different data structures.
System call
API to OS
- Provides ways of calling facilities and services in kernel (e.g talking to hardware)
- Not the same as normal function call ( Have to change from user mode to kernel mode)
There are less restriction in kernel mode.
-
Majority of syscalls have a lib version with same name and parameters. This is call the function wrapper. e.g getPID()
-
There are few lib function that present a more user friendly version to programmer, this is a function adapter (Lesser para, more flexible para values) e.g Printf -> write
-
No wrapper Direct long syscall (…..)
General system call mechanism
- User prog invokes the lib call
- Lib call places the sys call number in a location thats desinated e.g reg
- Lib call exe a special inst to switch from user mode to kernal mode This is called TRAP or syscall. This instruction depends on the architecture.
- In kernel mode, the appropriate sys call hadnle is determine
- Sys call handler is executed We cannot directly call the function, we need a wrapper or interface to allow us to move to the kernal mode to exe the code in the syscall. The prog cannot directly invoke the kernel mode.
- Sys call handler ended
- Lib call return to user program
User Mode
Get pid will set up syscall num, call trap. We put the number if the call into some register and execute instruction (ie syscall) Most of the time it is in register 17
Kernel mode: Dispatcher can be done is software or hardware. It can lead directly to syscallhandler which perform the task.
User Mode: return back The value is intact
The boundary of the kernel and user mode is crossed only by hardware ensure that no user program can run something that is privilege (System security)
Exceptions and Interrupt
Executing a machine level instruction can cause exception (i.e., stack overflow, division by 0)
Exception is synchronous
- Occurs during program execution
Effect of exception:
- An exception handler is executed automatically
- Similar to a forced function call
Asynchronous is more complex to handle as it can happen anytime
Interrupt
External events can interrupt execution of program
Usually hardware related:
- Timer, mouse movement, keyboard press
(Find out what is TRAP/EXCEPTION/INTERRUPT) Interrupt is asynchronous
- Happen anytime
Handler
- save register/cpu state
- Perform handler routine
- Restore
- Return from interrupt
Might behave as if nothing happen
What if there is a memory data that is on route when suddenly, an interrupt of the highest priority appears. What does the OS do? The operating system cannot be involve with the implementation of the instruction. (it cannot control if the OS get dropped) A software cannot copy data between hardware buffers, nor drop
Interrupt e.g
There is an interrupt vector table. lets say there is some instruction at PC and we want to load this memory into register, The stack will go downwards.
lets say instruction load reg1, memA 3 byte
- Code for load
- Register number
- Address for memA
There are multiple hardware steps: 1) Read one byte from address found in PC Put byte into temporary register (IR), increment PC by one 2) Decode and realized it is a load, it needs an address 3) Read two more bytes Increment the PC by 2 4) Read the source operands The actual execution of the instruction
Interrupt!!!<
5) Ignore interrupt and perform ALU operation 6) Store result into destination operand Interrupt pending 7) Check if there is any interrupt pending (software) no? Go step 1 yes? Serve the interrupt
We are not serving the interrupt at “anytime” but only at step 7, when the current instruction is being served finished.
Handling steps
- PUSH status register
- PUSH PC
- Disrupt interrupts in status register
- Read interrupt vector table entry Check where is the address of interrupt
- PC<- ISR1 Jump there
- ISR1 execution Call function, go back to reading byte
(Step 1-5 is hardware, 6 is software)
ISR1 execution
- PUSH (reg to be modified) [software]
- Optionally enable interrupt (all or some) [software] depending on priority
- Do the necessary stuff Allow modify the push register
- POP (Modified reg)
5.IRET
specialised return from interrupt instruction
- pop status reg
- pop pc, return the main code
UNIX Case study
1) fork() Create a new process, a copy of the same process but it is a child. The child and the parent are in the same state so it continues.
WHY?
- The only difference between child and parent is the return value of fork In parent, the fork returns the ID but the child returns 0.
Both parent continue executing after fork() Common usage is to use the parent/child process differently e.g Parent spawn child to carry out some work e.g Parent is ready to take another order
childPID= fork()
//the childPID is 0, then the current running program is the child, else u are parent If we use an if/else we can determine who is child and separate the code accordingly
Independent memory space
IF we declare int var =1234 and we do fork(), var has it’s own memory space rather than sharing the same.
Different address space
Executing a new program/image
Fork() itself is not useful, we still need provide the full code for the child process. We can make use of the exec() system calls family to execute another existing program. One program to invoke the other. Exec replaces the process it is running with whatever you are running.
Command Line Arguments
Command line is pass to main class when we declare
int main(argc, argv[]){}
ArgC is the number of arguments pass inclusive of program name
Argv[] is an array of commands in string
Fork() + Exec()
Let me create a new parent/process and then create a copy. Replace the child with some other process. My parent can then wait for child to finish. The parent is responsible for the child cleanup.
The master Process
- Every process have parent
-
What is the last ancestors? - INIT is the root process
- Special init:
- init process
- PID = 1
- Created in kernel at bootup time
- Watches other processes
In the process tree, init is in the top of the hierarchy and below it is other OS processes.
Process Termination in UNIX
Return value will be return to the hierarchy ontop. We can always do echo ? to get the return value of the latest prog we execute
The function does not return!
Process on Exit
- Release most system resourccs on exit
- Some are not releasable e.g PID, status (parent-child sync) Process accounting info (CPU time)
Implicit exit() In main, it will implicitly calls exit()
- Open files get flushed
0 - normal term 0! - to indicate problematic execution
Parent child Synchronisation
Parent create child A, it then can
- Wait for it to terminate (If parent call wait, wait will wait for the child to finish and it gives a opportunity to sync with the child)
- Wait returns the PID of terminated child
Behavior
- The call is blocking
- Call fork
- Call exec to replace child’s code
- Some point the child exit
e.g what if the parent say wait after creating?
- The parent will get block
- When child finishes, the parent will continue
e.g What if parent does not call wait when child finish
- Child process has already terminated
- It still remains present as a zombie process / Orphan
- No one to clean up
- Parent has not clean wait
- It will assign a new parent to the child
- It will demaster process
- This is to clean up the child
Wait()
- One process exit: Becomes zombie
- Cannot kill something that is already killed
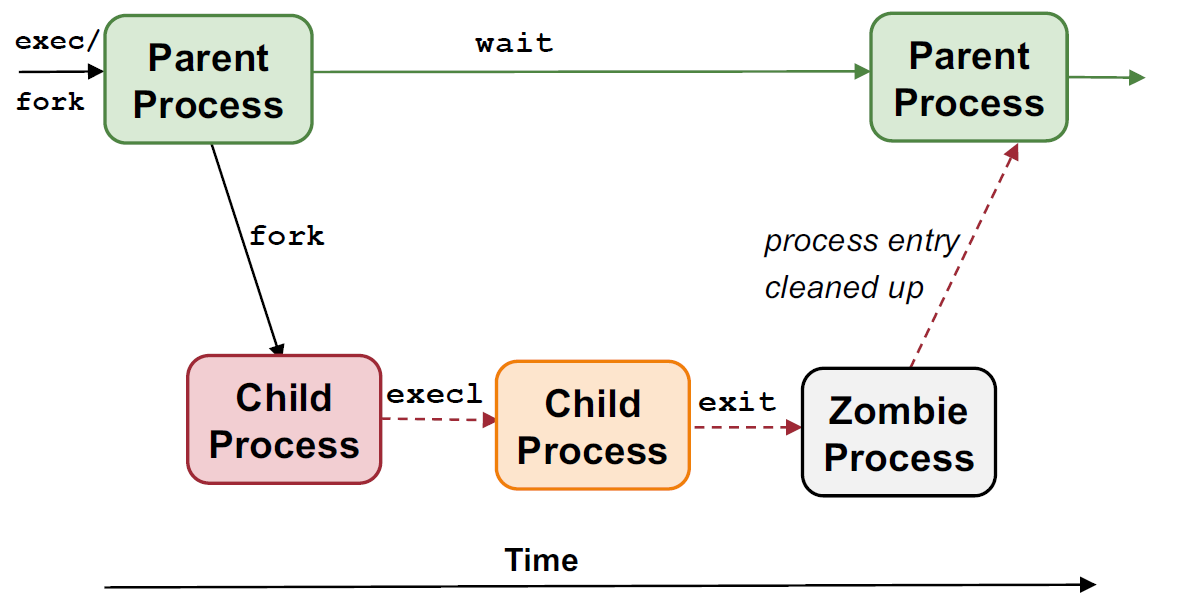
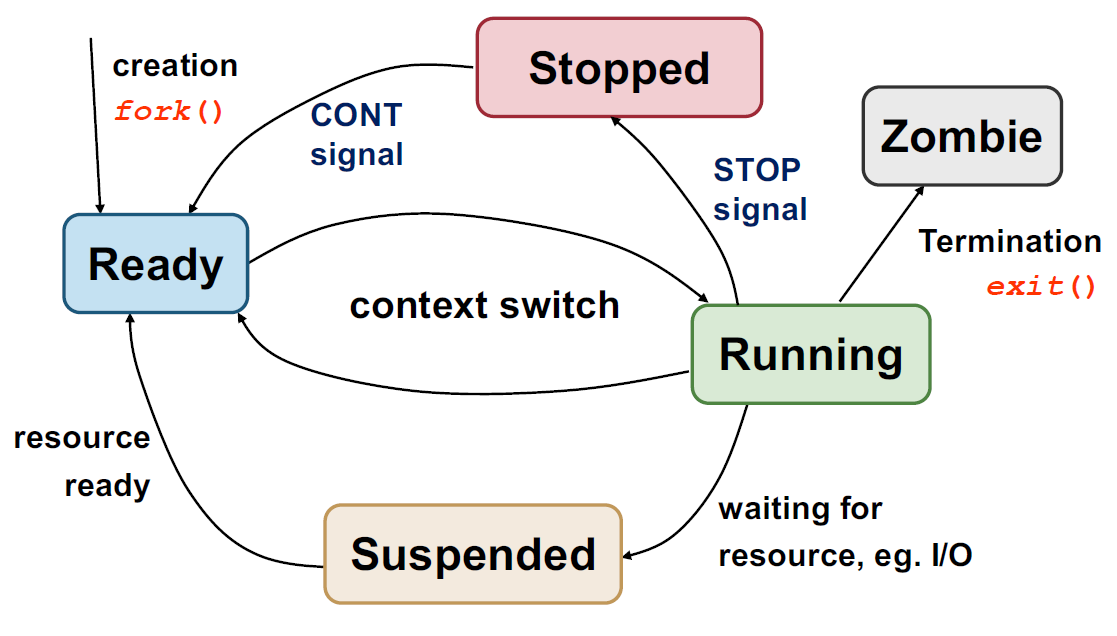
Process state diagram in UNIX
Fork() -> Creates ready process
- Kicks current process or current process is suspended (block)
- send signal that it can be ready
Why can’t it go from suspended to ready: Other process might be running
Scheduler looks at ready queue.
Stop state -> Linux can send a signal to process to stop it
Implementation Issues
Memory region info:
- text
- data
- Heap
- Stack
When doing a fork, they will create a PCB2 which clone the memory (replicated) But because we call exec(), this memory that was replicated is thrown away (Not good)
- Create address space for child process They have to be isolated
- Allocated pointer to new PID PID of child is different to parent
- Create kernel process data structure
- Copy kernel environment of parent process
- Init child process context
- Copy memory regions from parent Code, data, stack This is very expensive
- Acquired shares resources e.g Open files and dir
- Init hardware context Copy registers and init it
- Child can run now
Memory operation copy
Why are we copying these memory space if we are not going to use it? (child) But it is not guaranteed that we will call exec after fork. These are two system calls and are independent. How do I deal with this problem of wastefully calling operation.
The child is not able to access the whole memory range right away. They do not need the data. Perhaps we can trick the child? Trick the child that it is its own data but actually it is not.
-> The data is the same until someone modify something
Copy on write
- Duplicate a memory location when it is written to IF i have a parent data, and i want to copy the child data but do not actually want to copy. I want the child pointer to point to the same location. I am going to share this obj until one of them tries to modify. ONLY then, they will have individual copies.
This is to make fork a lightweight process (Attempt)
Note:
- Memory is org into mem pages
- Mem is manage on page level
Modern Take on fork
Fork() is like clone but modern A clone can create a copy of process without copying the entire address space
- Can decide what to share (key or stack) This is useful when we create something lightweight (e.g Thread)
Fork() is a wrap around for clone. However, it is not versatile
Lets say that we have a timer that generates an interrupt at some period, when we said sleep(), it will be woken up by interrupt Only if certain time Someone needs to take care on when sleep is called, need to wake up
there is a sleeping queue that stores all the sleep queue process. When interrupt is called, how to know which process to wake up without going through the entire queue
We can create a following list, sleep 100 - 20 - 30
for the call sleep(100) sleep (120) sleep(130) The following store the relatives from the first sleep call. When the timer interrupt comes, we check the first one. This structure works for processes that are waiting for some timer.
Wait vs Sleep
If we use wait, we are waiting for one of our child process to finish. Sleep waits for sometime to pass
How does fork relate to sleep queue It is not, It is about the block process.
Segmentation fault It is a generic fault. Once you are done with the fault, it usually go back to the original instruction It is a fault when you access the address that you did not have access. The OS will not allow you to continue.