Pipelining
Mips Pipelining
Can we go faster?
Instruction Execution =
Instruction Execution =
- Read contents from storage elemts
- Perform computation through some combination logic
- Write result to storage element
Single-cycle processor
Performance
We have to choose for the longest instruction time total as our cycle time
But because we choose the longest, sometimes instruction will finish early
To execute 100 instruction = 100 * 8ns = 800ns
We will define a cycle time for a single cycle processor.
The clock frequency we select is a sum of Tk where n is the number of stages for each Tk
The clock frequency we select is a sum of Tk where n is the number of stages for each Tk
Tk: time that is taken for each step
n: Number of stages for each Tk
n: Number of stages for each Tk
The total execution time for I instruction is cycle * cycleTime
Each Instruction takes one cycle to execute
Multicycle Implementation
- Break up instruction into execution steps
- Each execution steps takes one clock cycle (Shrinking cycle time, increase clock freq)
- Choose to enable certain stages for certain instruction
- Instructions don't take the same number of cycle to finish
Average CPI is the average number of cycles taken.
- Determine cycle time by choosing max cycle time
- Choose the avg CPI
- Total execution = I * AverageCPI * CT(multi for each of the cycles)
Pipelining
Stages
- IF (Instruction Fetch)
- ID (Instruction decode and Register Read)
- EX (Execute and Operation or calculate an address)
- MEM (Access an Operand in Data memory)
- WB (Write back the result into a register)
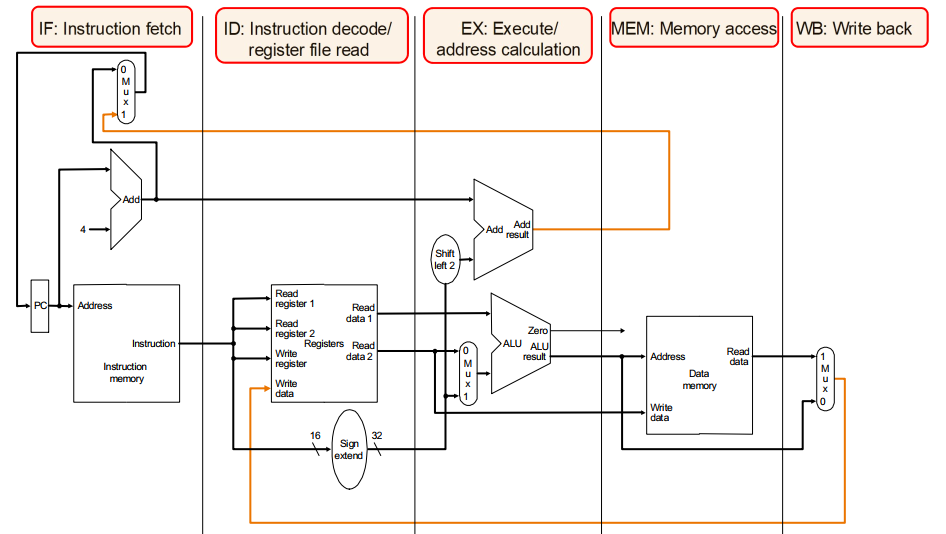
Datapath
These are pipeline registers, a latch that updates only when the clock is on the upper edge
These pipeline registers allow us to isolate the stages
(Shaded right side = read)
IF/ID
Read the instruction memory from PC and store it into the pipeline register. We also realised we store the PC+4. Instruction bits (32) will be memorised.
Read data 1 and read data 2, 16 bit immediate will be sign-extended to 32 bits.
ID/EX
- Register values read
- 32 Immdeiate value
- PC+4
EX/MEM
PC+4 is used to calculate the branch instruction
Why can't we just route it? Because its a pipeline processor so each time its doing many other stuff. We cannot pass the value to another component which might be doing something at the moment
- ALU Result
- isZero signal
- Read data 2 from the register file
MEM/WB
If its a store word instruction, it will use to store memory
- ALU result
- Memory read data
END
ALU data or memory data
Passback
Or it can use to store memory location
Needed:
- Data to be written
- Register number
We realised that the register number may not be correct because we use the current number in the decode stage to as the address but now we are doing pipelining, it might be the wrong value as it will be overridden.
Solution:
SO we will pass the value in write value through the pipeline continuously until it is in WB stage
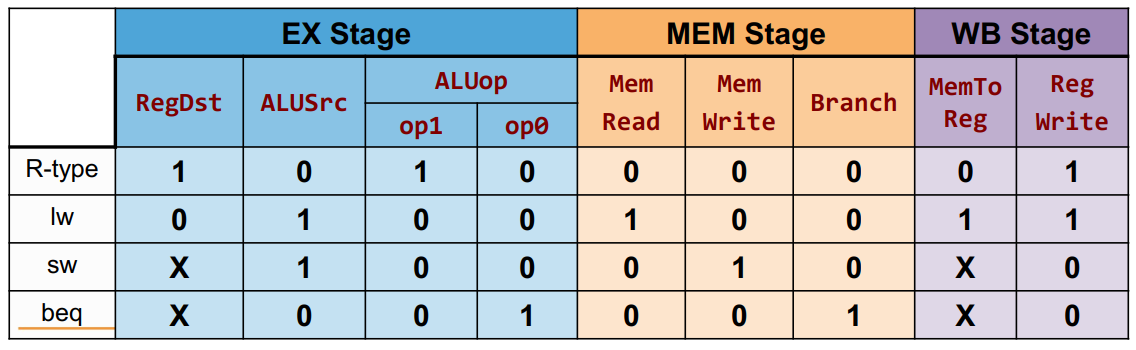
Pipeline control
Use control signals as a single cycle data path
Difference: When is that signal utilized
Control unit will control the signal and pass the value along the pipeline until it reaches the designated place.
Grouping
We ask when do we use the signals and group them at the stage where they are being used.
Pipeline Performance
Td - pipeline overhead e.g pipeline register
max(Tk) - longest stage time among the N stages
max(Tk) - longest stage time among the N stages
Cycle time:
CTpipe = (max(Tk) + Td) * (I + N - 1 )
is the cycle needed for I instructions
But what is the better speed up?
Ideal speedup
- Each stage almost the same time
- The summation is the same * number of stage
- Assume there's no pipeline overhead
- Number of instruction I is much larger than number stags N
These assumptions can also show how pipeline loses performance
Speedup = time (single cycle) / time (pipe)
= N (if I is very large compared to N)
Conclusion: To increase speedup, increase N where N is the number of stages
Pipeline Hazard
3 Problems:
- Structure hazard caused by hardware resources
- Data hazard caused by data dependency
- Control Hazard caused by the change in program flow
Structure Hazard
Let say we only have one single memory module.
When we go through the pipeline, check if we use the same hardware twice in a clock cycle.
We cannot have two instructions using the same hardware.
We cannot have two instructions using the same hardware.
Stall the pipeline
Ask the instruction to stall until the problem goes away, then continue. Every instruction will have a NOP which is an or $0 $0 $0 which stall one cycle
But it will cause a bubble and will waste time
Or it can use to store memory location
Separate Memory
Split memory into 2 separate modules: data and instruction. Instructions like LW can use data memory while INST can use instruction memory
Using this idea, even when they access, its two separate modules. Thus we can access the memory twice.
Read after Write register
Occurs when a later instruction readds from destination register written by an earlier instruction. (True data dependency)
Register file access is quick to access to read and write such that it can 2 instruction in one cycle. One cycle has an upper edge/lower edge, we can read/write during these two different cycles.
Data Hazard (Data dependency)
When the relationship between instruction prevents pipeline execution.
RAW (Read after Write)
i1: add $1, $2, $3
i2: sub $4, $1, $5
If the processor did not do properly, it will read the old data rather than the updated data.
There is no way we can avoid this (true data dependency).
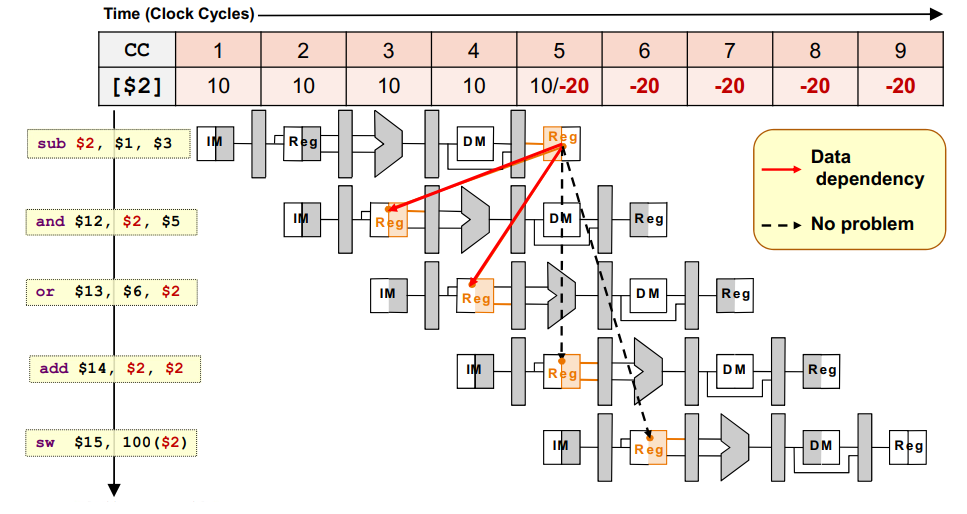
Forwarding
- Forward the result to any trailing instructions before it's reflected in the register file
Because the latest time we can get the value is right after ALU, we will store it in a latch (ex/mem or Mem/wb)
- Bypass the data read from the register file
What if the instruction is a load word?

The calculation is done one step away from the use of the register. We have no choice but to stall since lw at cycle 5 but needed in cycle 4.
We have to use a stall instead.
Control hazard (Control dependency)
An instruction depends on another instruction to know if it gets executed (e.g branch)
If control is not handled properly, it might cause an incorrect execution that might change values incorrectly.
e.g
beq $1, $3, 7 (PC+4) + (7*4)
IF
Branch will be store into latch at end of the cycle.
PC will produce 44 which is the next instruction
Branch will move to decode stage
PC will be 48
BEQ will move over while PC = 44 will move to IF stage
By the time we decided whether to take the branch, there will be other instruction in the processor already. -> TOO LATE
Stall
We need to stall until the branch reaches the mem stage (3 cycles)
But 3 cycles is very heavy.
Early Branch resolution
Make the decision in ID stage instead of MEM
Make the decision in ID stage instead of MEM
1. Calculate branch target address
2. Check the condition of a branch instruction
We will try to move the calculation earlier, make the decision in the ID stage rather than EX stage.
In the decode stage, at the end of cycle 2 we wait for branch outcome and reduce 1 clock cycle delay.
But this will break the code which forwarding cannot solve (Due to past back in time)
We will use stalling as well.
Then we will then include a new path for the branch instruction from ALU to ID stage
This will add on another clock cycle delay.
But we will realise when we load follow by branch since we only get the correct value in the register after it reads the memory, we have to forward the memory from mem/wr latch but it's going back in time again (decode stage of branch), so we need double stall.
This will add on another clock cycle delay
-> Total is 3 clock cycle
But compiler can do something useful in this case, we can do other instructions
-Theres no other ways to improve this method-
Branch Prediction
We predict that all branches are not to be taken. We treat the branch as if it's not taken
Not taken:
Guess correct
-no Pipeline stall
Taken:
Guess wrongly
-> Wrong instruction
-> Flush successor
We set all the latch to 0
It's safe to let them go in and because the mem and write are at the later stage, the killed of instructions will not reach there.
Total instructions = 1 + 10*2 (loop) +1
Ideal pipeline = 4 + 22*1 = 26 cycle //only first instruction is overhead and we ran the code once
Delayed Branching
Since we are waiting for X cycles,
why not do something meanwhile.
"Branch-delay slot"
We need to find another instruction to move into.
e.g
When we see beq, we will need to delay 1 cycle,
We will look ahead from the branch for another independent instruction and execute them.
Those instructions are going to be executed regardless of the branch.
e.g
or xxxxxxxx
beq xxxxxxxx, exit
(Empty slot for independent instruction here)
Xor xxxxxxxxxx
exit:
- Because Or does not depend on the branch and will execute anyways, it is moved into the slot.
- So while the BEQ is calculating, it will run OR
But what if we cant find an instruction?
- Nop
why not do something meanwhile.
"Branch-delay slot"
We need to find another instruction to move into.
e.g
When we see beq, we will need to delay 1 cycle,
We will look ahead from the branch for another independent instruction and execute them.
Those instructions are going to be executed regardless of the branch.
e.g
or xxxxxxxx
beq xxxxxxxx, exit
(Empty slot for independent instruction here)
Xor xxxxxxxxxx
exit:
- Because Or does not depend on the branch and will execute anyways, it is moved into the slot.
- So while the BEQ is calculating, it will run OR
But what if we cant find an instruction?
- Nop