Hashing
Problem: Find me a thief.
Want to look through a database of criminals based on fingerprints. Each lookup should be very fast.
We need to look for an ADT.
Dictionary ADT
Operation with k = key and v = value
But it is not ordered
Implementation using Data Structure
Insert Time:
Unordered Array/Linked List: O(1)
Ordered Array/Linked List: O(n)
Balance Binary Tree (AVL): O(logn)
Average search time:
Unordered Array/Linked List: O(n)
Ordered Array/Linked List: O(logn)
Balance Binary Tree (AVL): O(logn)
Insert [61 week 9]
But Hashing is O(1) search time..?
Hash table does not use order comparisons. (The fastest order comparisons is O(nlogn))
HashTable:
Insert - O(1)
Avg Search time - O(1)
Avg Max/min - O(n)
Avg Floor/Ceiling - O(n)
Hash Tables
Insert and search is O(1)
But its not that good.
1. It takes up too much space, (2^64-1)
2. If keys are not integer
Chaining (Separate Chaining)
If there's collision, we will add it to a linked list.
This is to store multiple values in a bucket
This is to store multiple values in a bucket
The worst case space complexity for hash table with separate chaining
=> O(m+n)
-> n is linked list worst case, m is worse case for filling up everything in hashtable
-> mn is not possible because there are only n keys
Inserting takes O(1) time
-> Hashing key takes O(1)
-> Insert to bucket takes O(1)
-> Insert to linked list is O(1)
Searching takes O(n) time
-> Accessing the hash tables takes O(1)
-> Searching linked list is O(n)
Simple uniform hashing assumption
There is a low probability of collision
- Optimistic assumption
- Every key is likely map to every bucket
- Keys are map independently (Random cases and collision is look over)
Average Search Time under (Simple uniform hashing assumption) is O(1)
Expected search time = 1 (Hashing + array access) + expected # items per bucket (Linked List traversal)
Expected Maximum cost of search for chaining is O(logn) [Extra]
Chaining With other Data structures
AVL is O(logn) but have a lot of overhead (Memory + computational time) for small number of items
Open Addressing
When collide, probe until can find an empty slot.
Load Factor
Load factor = Number of keys in the hashtable/ Size of hashtable
Load factor determines how much of the table have been use.
Linear Probing
Keep checking next bucket till find an empty slot.
Index i = (baseadd + step *1) mod m
Index i = (baseadd + step *1) mod m
Searching
Keep probing till we find a key match, we stop when we hit a null
Deleting
-> When a new key is inserted, the probability of it being under the big cluster is bigger.
The bigger the table becomes the worst the efficiency is.
With linear probing, big cluster are more likely to form
Quadratic Probing
Squaring the steps. If I cannot insert in the next key, I will jump ^2 steps. This is to prevent clustering.
Index i = (baseadd + step ^2) mod m
Problem with Quadratic is that it will cause secondary clustering
Index i = (baseadd + step ^2) mod m
Problem with Quadratic is that it will cause secondary clustering
Secondary Clustering
If two keys have same probe position, their prob sequences will be the same.
Clustering around different points
There are m probe sequences
Theory: If load factor is 1/2 and m is prime, then empty slot will always be found
Prove by Contradiction:
Consider two probe locations,
step x and y
where x < y < m/2

Prove by Contradiction:
Consider two probe locations,
step x and y
where x < y < m/2
Double hashing
Using a second hashing,
index i = (hash1(k) + step * hash2(k)) mod m
We have m^2 indexing sequences
Double hashing will allow us to avoid secondary clustering if hash2(k) is relative prime to m
This also will ensure that we hit all buckets.
The average cost of insert (SUHA) and m=n is not O(1) nor O(nlogm) nor O(m+n)
-> We are depending on the load factor.
=> 1/(1-a), a is load factor
=> 1/(1-a), a is load factor
But the average cost of insert (SUHA) and a=0.5 is O(1) where a is load factor (How full the hash table is allow to get before max is increase)
But double hashing takes more time.
But double hashing takes more time.
Chaining vs Open addressing
Addressing:
- Better memory usage (Cache performance)
- No references / Dynamic memory allocation
- Linear addressing
Chaining (Separate):
- Less sensitive to hash function
- Less sensitive to load factors (open addressing degrades past a = 0.7)
Average is O(1) but if assumptions are met
Hashing Functions
What is a good hash function?
- Consistent: Same key maps to same buckets
- Fast to compute
- Scatter the keys into different buckets as uniformly as possible
- Consistent: Same key maps to same buckets
- Fast to compute
- Scatter the keys into different buckets as uniformly as possible
Hash Functions
We do not need to have an array the size of the universe. We will map actually keys into a bucket
Hash function takes in a key and map it to some value {0 to m-1} where m is the number of buckets
Assuming computing h takes O(1) <- this is not true in practice
Collision:
If two distinct key map to the same bucket.
Pigeonhole principle - There will always be one hole with two pigeons. There will always be a collision if the number of holes are smaller or close to number of pigeons, there will be more collision.
Adding assumption,
Assume:
- we have n keys and m is almost equal to n buckets
- keys are uniformly distributed
-> Summing the strings using ascii?
-> Sum the letters (e.g A-> 1, Z -> 26)? (NO)
We want hash function whose values look random, like a random number generators
Common techniques:
- Division
- Multiplication
x(n+1) = (aX[n] + c)mod m
where a, c and m is random numbers
Methods
Division method
h(k) = k mod m
m should not share common factors with k as we do not want to skip cells.
m should not share common factors with k as we do not want to skip cells.
Choice of M:
How can I use shifts to compute k mod m.
if m = 2^x, because its very fast
k - ((k >> x) << x)
->We shift right and left to remove the remainder
->Take the k and minus the answer to get the lower ordered bits
But does this scatter the keys into different buckets as uniformly as possible?
-> No
=>Reason:
Imagine what happen if all the input keys are even?
If all the input keys are even then k mod m must be even.
k = im + k mod m, where im is some multiple of m
if k is even, im is even so kmodm is even
This will cause us to have even pockets and will never hash to an odd pockets.
-> fast to compute but waste half the space
Assuming chaining, how much of the table do we use if both x and m have a common divsor d?
1/d
-> Using the prev answer where even is using half the space ie (1/2), 2 is the divisor for even.
If its d as divisor then its 1/d
Conclusion:
- Choose m to be Prime, avoid powers of 2 and 10
- Not always effective
- Slow (no more shift)
Conclusion:
- Choose m to be Prime, avoid powers of 2 and 10
- Not always effective
- Slow (no more shift)
Multiplication method
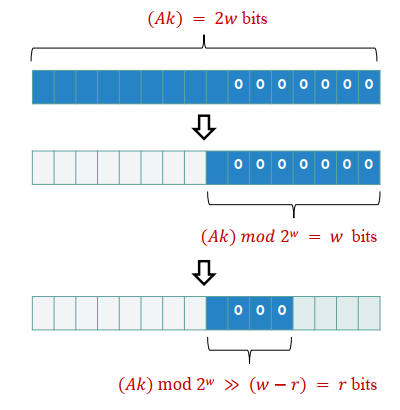
Table size: m = 2^r
Constant: 2^(w-1) < A < 2^w
h(k) = (Ak) mod 2^w >> (w-r) , w is size of keys in bits , r from table size, A is constant
We can't let A to be even because we will be multiplying a shift
=> Odd * even = even
=> The last few digits will be 0
=> Cause at least one bit of information loss
=> The last few digits will be 0
=> Cause at least one bit of information loss
Table Size
Assumption:
- Hashing with chaining
- Simple uniform Hashing
- Expected search O(1+n/m)
- Optimal Size: m = cn
m < 2n : too many collision
m> 10n : too much space
But we don't know n in advance
Dynamic Table size
Grow and Shrink the table size as necessary
We cannot just copy the old table to new table because the hashing uses the table size.
1. Choose new table size
2. Choose new hash function h2 that matches m2
3. For each key-value pair ki,vi in the old hash table
- Compute new bucket b2 = h2(ki)
- Insert (ki, Vi) into bucket b2
Costs:- Creating new table: O(m2)
- Scanning Old hash table: O(m1)
- Insert all n elements into new table : O(n)
Total: O(m1+m2+n)
Increment by 1
If table is not full, ci = 1
If n = m (table is full) , then expand so ci = i [new table]+ (i - 1) [old table] + 1 [insert] = 2i
// we need to copy over, expand and calculate more
What is the total cost to insert n elements into the table? O(n^2)
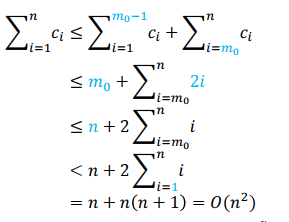
We use

to plug in.
But the average for insert (amortized) is O(n)
(Total cost divided by the number if elements which is n)
Amortized-> totalcost/ numberofElements
Amortized-> totalcost/ numberofElements
Doubling the size
If n<m, ci = 1
If n = m (table is full), then expand so , ci = 2i + (i-1) + 1 =3i
- table is full only when i is an exact power of 2
The total cost to insert n elements is O(n),
The amortized cost for insert is O(1)
The amortized cost for insert is O(1)
j is the number of resizing we need,
Resize each time we reach full then we double it
2^ j = n
j = log[2]n
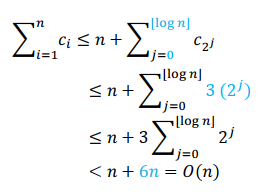
Using the method
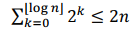
Average is O(1)
In conclusion, we use double the size
Cost of resizing including worst case insertion: O(n)
But on average is O(1)
Square the size
Cost of inserting n elements: O(n^2)
Cost of inserting (amortized) n elements: O(n)
Amortized Analysis: Accounting Method
Operation has amortized cost T(n) if for every integer k, the cost of k Operation is <= kT(n)
- We will have a charge amount for each insert
- Ensure bank account is always big enough to pay for resizing