Problem: Find customers spending between $a and $b where b>a
How fast can we find customer who spend $a in an unsorted array?
-> o(n) [Linear search]
We are not given any information so we have to look one by one.
BUT!!! Our array is sorted..
Strategy: Exploiting structure
If our Array is already sorted, and we want a value that's less than e.g 11,
we should search the left of 11.
Binary search
function binarySearch (A, key, n)
low = 0 high = n - 1
while low <= high
mid = (low + high )/2
if key < A[mid] then
high = mid - 1 //the key is below the mid, so our high is now mid
else if key > A[mid]
low = mid + 1 // the key is above the mid, so low is now mid
else
return mid //we found it! やたあああああ
return not_found //not found 残影 :(
low = 0 high = n - 1
while low <= high
mid = (low + high )/2
if key < A[mid] then
high = mid - 1 //the key is below the mid, so our high is now mid
else if key > A[mid]
low = mid + 1 // the key is above the mid, so low is now mid
else
return mid //we found it! やたあああああ
return not_found //not found 残影 :(
Key is the number we want
Checking algorithm correctness:
Precondition:
Precondition: Condition that is true before some set of operation
(Like loops or function)
1. Sorted
2. A is of size n
Postconditions:
Postcondition: Condition that is true after some set of operation
(like if else)
1. A[mid] = key
2. or key is not found
Invariants
Its a condition that is true during some execution of a program or a set of operation
Loop Invariants:
A condition that is true before and after each iteration of a loop
1. The key must be between low and high if the key is in the array
2. Work through the loop and consider each case
Loop Termination:
A[mid] = key
or high < low (not_Found)
This is the desired results
HOWEVER, THE BINARY SEARCH IS NOT EXACTLY CORRECT
Time complexity:
O(logn)
O(logn)
Each iteration, we divide the search by 2
Iteration k: n/(2^k) = 1
1 is the base element
1 is the base element
k = logn
Space Complexity:
O(1) - We are not creating new memory, its bounded by constant
Divide and Conquer
1. Split into subproblems
2. Solve recursively
3. Combine solutions for each subproblem to produce a solution to original problem
start = findIndex(customers, $a)
end = findIndex(customers, $b)
for (int i=start; i<=end; i++)
println(customers[i])
end = findIndex(customers, $b)
for (int i=start; i<=end; i++)
println(customers[i])
This is n time complex because the for loop is n time complexity
Duplicates
There is something wrong with the algorithm.
-> IF there are people with the same amount, we will miss them out
Instead we need to find the first index rather than find index
Binary search to find First index
1. Find the index using binary search
2. If find the first number, use binary search to decrease the high pointer till the next number
in the left is another number (Find last number)
function binarySearchFirst (A, key, n) low = 0 high = n – 1
result = not_found while low <= high
mid = (low + high)/2
if key < A[mid] then high = mid - 1 else if key == A[mid] then result = mid
high = mid - 1 else low = mid + 1 return result
What is the worst case
computational complexity of
binarySearchFirst()?
A.
function binarySearchFirst (A, key, n) low = 0 high = n – 1
result = not_found while low <= high
mid = (low + high)/2
if key < A[mid] then high = mid - 1 else if key == A[mid] then result = mid
high = mid - 1 else low = mid + 1 return result
What is the worst case
computational complexity of
binarySearchFirst()?
A.
Time complexity of binary search first: O(logn)
Still binary searching for the first duplicate
- A is sorted
- A[mid] is the first occurrence of key
Still binary searching for the first duplicate
Precondition
- A is of size n- A is sorted
Post Condition
- A[mid] = key- A[mid] is the first occurrence of key
We can find the last index in a similar way..
However, there's a bug in the binary search
(mid = (low + high) /2)
This will overflow if low add high overflow
Merge sort
function mergeSort(A, low, high)
if low < high
mid = (high + low)/2
mergeSort(A, low, mid)
mergeSort(A, mid+1, high)
merge(A, low, mid, high)
if low < high
mid = (high + low)/2
mergeSort(A, low, mid)
mergeSort(A, mid+1, high)
merge(A, low, mid, high)
function merge(int low, int mid, int high)
for i = low to high
buffer[i] = A[i]
i = low
j = mid + 1
k = low
//Initialise
while i <= middle and j <= high
if buffer[i] <= buffer[j]
A[k] = buffer[i]
i++
else
A[k] = buffer[j]
j++
k++
// Iterate through helper.
// At each iteration, compare elements in both segments and copy smaller element over
while i <= middle
A[k] = buffer[i]
k++
i++
//Copy remaining items from left segement
L is buffer[low,...,mid]
R is buffer[mid+1,...,high]
The array A contains sorted elements of L and R
The loop invariant:
for i = low to high
buffer[i] = A[i]
i = low
j = mid + 1
k = low
//Initialise
while i <= middle and j <= high
if buffer[i] <= buffer[j]
A[k] = buffer[i]
i++
else
A[k] = buffer[j]
j++
k++
// Iterate through helper.
// At each iteration, compare elements in both segments and copy smaller element over
while i <= middle
A[k] = buffer[i]
k++
i++
//Copy remaining items from left segement
L is buffer[low,...,mid]
R is buffer[mid+1,...,high]
The array A contains sorted elements of L and R
The loop invariant:
The pointer must be between 0 and mid
and another pointer between mid and high
Time complexity: O(n) //from while
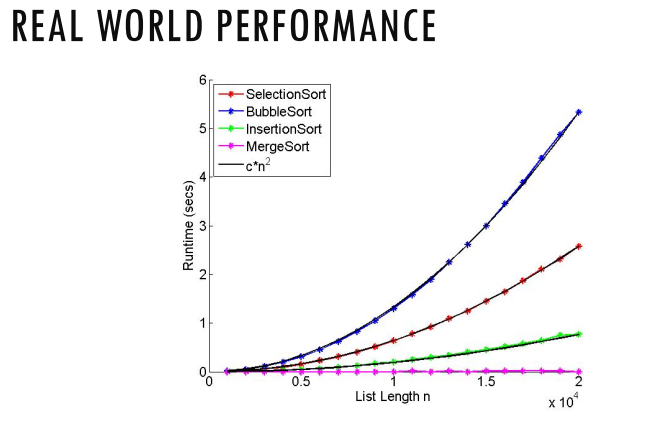
Total Time Complexity: O(nlogn)
Merge sort is logn
Merge is n
Mergesort:
Recurse Downwards
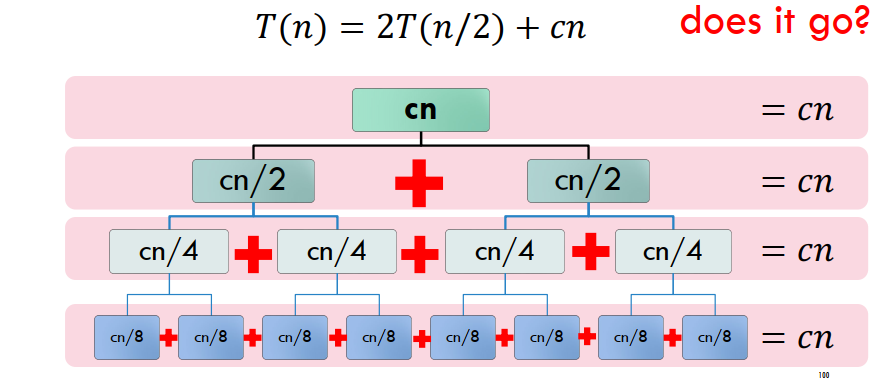
n=2^h
O(nlogn) is the fastest for comparison based sort